Understanding community response to Warburton MTB project
The Mountain bike park planned for Warburton has been extremely controversial with social and environmental concerns regularly voiced by critics. An Environm...
The Mountain bike park planned for Warburton has been extremely controversial with social and environmental concerns regularly voiced by critics. An Environment Effects Statement, a comprehensive study of the environmental impacts of large infastructure projects was ordered. One of the steps of the ESS is a call for community feedback. The community feedback for the Warburton MTB project was conducted in late 2021 and the responses were made public in early 2022. There were over 2500 submissions from the general public, including mountain bike riders and environmentalists. In this post I will use some basic machine learning techniques for automatically analysing the text in the submissions with the aim of understanding whether the overall feedback was positive or negative. To do this the ess results needed to be downloaded from the repository holding them, the pdf files need to be converted into plain text and the results analysed for the sentiment. All of this work will be performed with Python.
The community submissions for the ESS can be found here. Taking a look at the individual files we can see that each file containing the submissions have the same structure https://engage.vic.gov.au/download/document/23728 where the number 23728 increased for each submission file. Looking at the submissions the structure of the submissions are similar layout.
To read a PDF using Python there are numerous libraries available. My preference is pdfplumber because it has an easy to use API to adapt it to particular use cases. To read a PDF using pdfplumber we just need to use the following code:
import ssl
import urllib
import pdfplumber
import io
all_text=''
url = 'http://engage.vic.gov.au/download/document/23671'
gcontext = ssl.SSLContext()
req=urllib.request.Request(url)
resp=urllib.request.urlopen(req,context=gcontext)
data = resp.read()
with pdfplumber.open(io.BytesIO(data)) as pdf:
for p in pdf.pages:
text = p.extract_text()
all_text+=text.replace('\n',' ')
print(all_text[:1000])
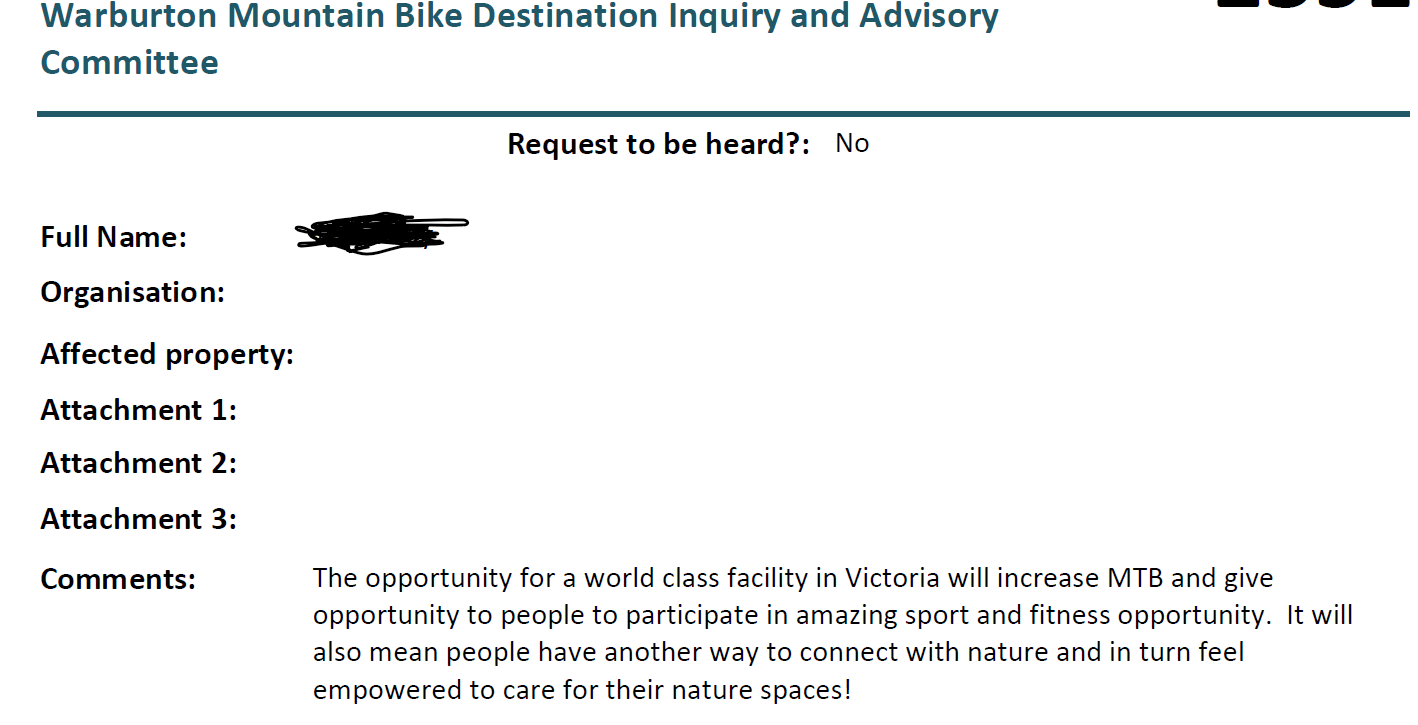
Submission Cover Sheet 1 Warburton Mountain Bike Destination Inquiry and Advisory Committee Request to be heard?: No Full Name: Andrew Gard Organisation: Affected property: Attachment 1: Attachment 2: Attachment 3: Comments: I believe this project should go ahead. It will create a wider community of mtb riders and also allow new people to get out and about in the nature on the trails of Warburton and surrounds. I believe it will bring more money into the local communities with hopefully, new businesses being able to open and create new job opportunities. Thanks, Andy.Submission Cover Sheet 2 Warburton Mountain Bike Destination Inquiry and Advisory Committee Request to be heard?: No Full Name: Mathew Stoessiger Organisation: Affected property: Attachment 1: Attachment 2: Attachment 3: Comments: I support the Warburton Mountain Bike Destination Project, the project will create jobs and enrich peoples lives through outdoor activities with minimal impact on the environment.Subm
Where we are downloading the PDF as a binary data file using urllib. We need to provide an empty ssl certificate to avoid missing certificate errors. If you wanted to reuse this code and adapt it to a different dataset you may not need this, or you may need to provide a valid certificate depending on the security of the source website.
pdfplumber.open() provides an object for accessing different elements of the pdf. For this example we want to extract all of the text from every page. This can be done by iterating over the pages in the pdf and using extract_text to retrieve the text. Here I am just going to use a string to store all of the text, because there is no guarentee that each page is a new submission. Long submissions may have multiple page comments and we ideally want to keep these together.
We can apply this process to all of the submissions by iterating over the filename. We can change the url of the submission using Pythons fstring formatting. Unfortunately, the submissions files are not numbered consecutively and some do not exist, to avoid crashing the code we can wrap the code in a try/except block.
all_text = ''
for i in range(23671,23728):
url = f'http://engage.vic.gov.au/download/document/{i}'
try:
gcontext = ssl.SSLContext()
req=urllib.request.Request(url)
resp=urllib.request.urlopen(req,context=gcontext)
data = resp.read()
with pdfplumber.open(io.BytesIO(data)) as pdf:
for p in pdf.pages:
text = p.extract_text()
all_text+=text.replace('\n',' ')
#
# import pdf files and save to text
#
except BaseException as e:
print(e, url)
HTTP Error 404: Not Found http://engage.vic.gov.au/download/document/23692
HTTP Error 404: Not Found http://engage.vic.gov.au/download/document/23694
HTTP Error 404: Not Found http://engage.vic.gov.au/download/document/23711
HTTP Error 404: Not Found http://engage.vic.gov.au/download/document/23712
# save all of the comments to a file to avoid re-downloading
import pickle
with open('warburton.pkl', 'wb') as f:
pickle.dump(all_text,f)
import pickle
with open('warburton.pkl', 'rb') as f:
all_text = pickle.load(f)#pickle.dump(all_text,f)
We now have a large string with all of the submission. We can see that every submission has the title page ‘Submission Cover Sheet’. To break the submissions into categories we can split the string into separate strings using the string function split.
submissions = all_text.split('Submission Cover Sheet')
submissions[1]
' 1 Warburton Mountain Bike Destination Inquiry and Advisory Committee Request to be heard?: No Full Name: Andrew Gard Organisation: Affected property: Attachment 1: Attachment 2: Attachment 3: Comments: I believe this project should go ahead. It will create a wider community of mtb riders and also allow new people to get out and about in the nature on the trails of Warburton and surrounds. I believe it will bring more money into the local communities with hopefully, new businesses being able to open and create new job opportunities. Thanks, Andy.'
Looking at an individual submission we can see that the text following Comment: is what we are interested in. We can extract all of the text following the comments by spliting the text after ‘Comments:’.
comments = []
for submission in submissions:
if 'Comments:' in submission:
comments.append(submission.split('Comments:')[1])
print(f'There are {len(comments)} submissions')
There are 2548 submissions
We now have a list containing the text for each comment. Now we want to determine whether the overall sentiment of the comment is positive or negative. Sentiment analysis is one of the techniques of natural language processing. Different models exist and its generally best to build a model using a training database. For this example, we will use a pre-trained model from the natural language tool kit. Before using the sentiment analysis we need to remove any uncessary words from the comments, these include “a, an, the for” etc.
import nltk
from nltk.corpus import stopwords
from nltk.sentiment import SentimentIntensityAnalyzer
# download the nltk files for the first run
nltk.download('stopwords')
nltk.download('vader_lexicon')
stop_words = set(stopwords.words('english'))
comments_no_stop_words = []
for comment in comments:
comments_no_stop_words.append([w for w in comment.split(' ') if not w.lower() in stop_words])
[nltk_data] Downloading package stopwords to
[nltk_data] C:\Users\lgrose\AppData\Roaming\nltk_data...
[nltk_data] Package stopwords is already up-to-date!
[nltk_data] Downloading package vader_lexicon to
[nltk_data] C:\Users\lgrose\AppData\Roaming\nltk_data...
[nltk_data] Package vader_lexicon is already up-to-date!
sia = SentimentIntensityAnalyzer()
sia.polarity_scores(' '.join(comments_no_stop_words[0]))
{'neg': 0.0, 'neu': 0.662, 'pos': 0.338, 'compound': 0.9062}
import pandas as pd
sentiment = pd.DataFrame([['',0,0,0,0]],columns=['comment','neg','neu','pos','compound'])
sia = SentimentIntensityAnalyzer()
for i, comment in enumerate(comments_no_stop_words):
r = sia.polarity_scores(' '.join(comment))
sentiment.loc[i,'comment'] = comments[i]
sentiment.loc[i,'neg'] = r['neg']
sentiment.loc[i,'neu'] = r['neu']
sentiment.loc[i,'pos'] = r['pos']
sentiment.loc[i,'compound'] = r['compound']
The results of the sentiment intensity analyser are four numbers specifying the negative, positive, neutral and compound sentiment. The initial objective was to determine what the split between negative and positive submissions for the Warburton mountain bike park. To do this we need to first validate how well the method works by looking at submissions for different sentiments.
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1)
ax.hist(sentiment['compound'])
ax.set_title('Sentiment of Warburton ESS')
ax.set_xlabel('Compound sentiment intensity')
_ =ax.set_ylabel('Count')

Looking at the distribution of compound sentiment intensity we can see that the majority of responses have a positive sentiment (compound intensity is positive). We can do a quick validation of this assesement by randomly selecting some comments within different sentiment bands to get an understanding of the results. To do this we will mask the pandas dataframe using a boolean mask and then use the random method to sample from the resulting dataframe.
old_column_width = pd.options.display.max_colwidth
pd.options.display.max_colwidth = None
sentiment.loc[sentiment['compound']>0.8,['comment','compound']].sample(2)
# pd.options.display.max_colwidth = old_column_widt2
| comment | compound | |
|---|---|---|
| 204 | My submission is simply a short commentary on the contents of the EES and the overall project direction, along with a personal story about the positive impacts of mountain bike trails. First of all, I do not claim to be an expert on any of the considerations considered in the EES –biodiversity, water, cultural heritage, land use, socio-economic or transport. However, upon digesting the contents of the report, it is apparent to me that the Warburton Mountain Bike Destination (WMBD) team have engaged with a broad array of experts in their field and have used that expertise to prepare an incredibly detailed statement of the effects of the project. I have seen firsthand the benefits of large, sanctioned trail centres. I grew up in Alberta, Canada, and through the fantastic trail networks in Kananaskis Country at Moose Mountain and West Bragg Creek, I had the opportunity to get involved in mountain biking from a young age. That opportunity resulted in me becoming a keen mountain biker, and as I spent long hours and days on my bike in Kananaskis, I developed a love for and connection to the area. That connection had two significant impacts on my life: 1. I care deeply about the beautiful natural places that I am so fortunate to enjoy on my mountain bike. When there were proposals to clearfell an area of Kananaskis near the mountain bike trails, I along with many mountain bikers voiced opposition to the project. It was clear that the members of the mountain bike community had become connected with the land, and did not want to see it destroyed. Many of us would not otherwise have known or cared about the logging that was to occur, but mountain biking taught us about the environment, and we cared enough to make a difference when it was threatened 2. Speaking of the mountain biking community, we all came together around a shared passion. This generated many connections for all of us that we may not otherwise have had. In this age of profound disconnection and isolation, we should be taking any opportunity we can find to build these sorts of communities and let them thrive. In the years since I have moved to Victoria, I have used mountain biking as a vehicle to get to know the incredible beauty of this state. I would love to see more Victorians get the opportunity to get on their bikes and through the experience of mountain biking develop deep connections with their fellow mountain bikers, and the natural beauty around them. I would love to see more people making a living off nature-based tourism rather than resource extraction. In fact, if we consider the opportunities of investing in initiatives like this that would create jobs that do not require constant resource depletion, it could be argued that the environmental impact of building the trail centre would be a net positive. And lastly, as a mountain biker from overseas, I would love to see more mountain bikers come to experience all that Victoria has to offer. | 0.9978 |
| 2417 | Mountain biking is a growing sport and pastime for many people of all ages and sexes. It is a great way to exercise, socialise and have fun. It is also fantastic to get out into nature. Which just about all mountain bikers love and respect. As it is a growing sport there are a big lack of places to ride. We often travel hours to get to a place to ride. Having another place as awesome as Warburton to ride would be incredible and also take some pressure off other riding places and also help stop illegal tracks being built. Looking at Tasmania as an example of Mtb and locals coexisting together very well this can only be a great thing for Warburton and mtbrs alike. | 0.9761 |
sentiment.loc[(sentiment['compound']<0.8) & (sentiment['compound']>0.6),['comment','compound']].sample(2)
| comment | compound | |
|---|---|---|
| 764 | I believe that this project will be a great economic and social benefit for the area. | 0.7964 |
| 2389 | I love exploring new places on my bike and this would be close to home | 0.6369 |
sentiment.loc[(sentiment['compound']<0.2) & (sentiment['compound']>-0.2),['comment','compound']].sample(2)
| comment | compound | |
|---|---|---|
| 317 | The northern trail network located primarily in the Yarra Ranges National Park, making up just over third of the trails, should be abandoned. The southern trail network, just under two-thirds of the trails, occurs mostly in state forest and could proceed with some modification. The key issues are with proposed tracks in the Yarra Ranges National Park. National Parks are supposed to give nature the strongest of protections, yet parts of the project will cause undue harm to very important ecological values, removing important habitat, impacting on threatened plants animals and communities, water catchments while increasing pest species. This is neglectful of heritage and socio-economic values and the integrity of national parks. | 0.0000 |
| 958 | Mountain bike tourism is absolutely booming and will continue to do so. What has been designed for Warburton will be an absolute boon for the region and bring all manner of economic and community benefit —as was shown in the work done prior to the EES. Now with the EES documents completed and more in-depth empirical work completed than any other mountain bike trail network in the world, the data shows that there will be almost zero negative impact on the environment or the community. If this project does not go forward it will be an absolute travesty and a huge loss for the folks who live in Warburton as they stand to gain the most from these trails. | -0.1832 |
sentiment.loc[(sentiment['compound']<0.2) & (sentiment['compound']>-1),['comment','compound']].sample(2)
| comment | compound | |
|---|---|---|
| 1361 | Millions of Australians now ride mountain bikes for recreation and fitness, instead of spending millions of dollars flying overseas and to Tasmania to ride world class trails let’s build something in our own backyard! It would be a disaster if this project didn’t get off ground due to a handful of ill informed and unhappy people who aren’t interested in others being happy. “Build it and they shall come…… “ | -0.3595 |
| 1554 | I object to the development of new mountain bike trails in Warburton in the Yarra Ranges National Park. It will negatively impact on local wildlife that the park is set out to protect and extra human traffic will bring further environmental stress upon an already underfunded National Parks system in Victoria. | -0.0516 |
A common technique for visualising text datasets is to generate an image with all of the unique words weighted by their frequency of occurence. These word clouds can help to identify which words are most commonly used in a text to give some idea about the meaning.
from wordcloud import WordCloud, STOPWORDS
wordcloud = WordCloud(
background_color='white',
max_words=200,
max_font_size=40,
scale=3,
random_state=1 # chosen at random by flipping a coin; it was heads
).generate(str(sentiment['comment']))
fig, ax = plt.subplots(1, figsize=(12, 12))
ax.axis('off')
ax.set_title('Word cloud for all submissions')
ax.imshow(wordcloud)
<matplotlib.image.AxesImage at 0x1640d371c08>

from wordcloud import WordCloud, STOPWORDS
import matplotlib.pyplot as plt
wordcloud = WordCloud(
background_color='white',
max_words=200,
max_font_size=40,
scale=3,
random_state=1 # chosen at random by flipping a coin; it was heads
).generate(str(sentiment.loc[sentiment['compound']<-.5,'comment']))
fig, ax = plt.subplots(1, figsize=(12, 12))
ax.set_title('Word cloud for negative submissions')
ax.axis('off')
ax.imshow(wordcloud)
<matplotlib.image.AxesImage at 0x1640fe556c8>

from wordcloud import WordCloud, STOPWORDS
import matplotlib.pyplot as plt
wordcloud = WordCloud(
background_color='white',
max_words=200,
max_font_size=40,
scale=3,
random_state=1 # chosen at random by flipping a coin; it was heads
).generate(str(sentiment.loc[sentiment['compound']>0,'comment']))
fig, ax = plt.subplots(1, figsize=(12, 12))
ax.set_title('Word cloud for positive submissions')
ax.axis('off')
ax.imshow(wordcloud)
<matplotlib.image.AxesImage at 0x1642133e748>

From the results we can see that the majority of submissions were presented in a positive tone, indicating that these submissions were positive towards the development of the Mountain bike park as it is difficult to write a response with a positive tone that has a negative meaning. Some of the submissions classified as negative are negative towards the process or delays in building the park. Other negative sentiment submissions are true critics of the mountain bike park.
In this post I have employed very basic tools in natural language processing applying a generic model to a fairly specific problem. For this reason, the results should only be viewed as a coarse indication of the true sentiment in the submissions. The goal for this example, was to quickly (and automatically) understand whether there were more positive responses or negative responses. I did not want to read every submission.
Triangular meshes can be used for representing surfaces in 3D, can be used for interpolation and other modelling.
You can extract a triangular mesh using marching cubes over a volume of interest or build the mesh to fit a specific geometry.
However, in some cases a complicated mesh is not required.
In my case, I am trying to add a surface into LoopStructural which represents the elevation.
The elevation data has been resampled from a raster image, so there can only be a single elevation value for each pixel.
There are a few ways I can add the surface for visualisation:
To keep the process simple and as efficient as possible I will use the second approach and will do this using numpy arrays. This approach divides a square into two triangles as below.

To apply this to a cartesian grid we need a way of indexing the grid elements and determining which vertices are corners for which cells.
We can define two indexing systems:
Each cell has four corners, the origin of the cell (node 0 in the above diagram) is the vertex where i=ci, j=cj. The other cells can be defined as (i=ci+1, j=cj), (i=ci+1,j=cj+1) and (i=ci, j=cj+1).
We can apply this to every cell in the grid to get the corner indices. This short snippet of code shows how to do this in python using numpy.
import numpy as np
# define the vertices
origin=[0,0]
maximum=[1,1]
nsteps = [10,10]
x = np.linspace(origin[0], maximum[0], nsteps[0]) #
y = np.linspace(origin[1], maximum[1], nsteps[1]) #
xx, yy = np.meshgrid(x, y, indexing='xy')
# define the cell indexes
ci = np.arange(0, nsteps[0] - 1)
cj = np.arange(0, nsteps[1] - 1)
cii, cjj = np.meshgrid(ci, cj, indexing='ij')
corners = np.array([[0, 1, 0, 1], [0, 0, 1, 1]])
i = cii[:, :, None] + corners[None, None, 0, :, ]
j = cjj[:, :, None] + corners[None, None, 1, :, ]i and j are 9x9x4 arrays showing the node corner indices for every cell in the model.
For convenience we will convert from i,j indexing for the vertices to a global index. This can be calculated as i+j*nstep[0]. We can then convert the vertices to a Nx2 array of points.
# reshape the array so that its Nx4, either use -1 so
# numpy guesses the shape or define as i.shape[0]*i.shape[1]
gi_corners = (i+j*nstep[0]).reshape(-1,4)
# flatten xx, yy and then stack vertically, then rotate
vertices = np.vstack([xx.flatten(),yy.flatten()]).TWe now have an array that has the corner indexes for every cell and another array containing the location of the vertices. To extract a triangular mesh from this we need to generate an array of triangle indices. Using the relationships shown in the diagram above the triangle indices are tri1 = [0,1,3] and tri2 = [1,2,3]. We can use numpy slicing to extract the two triangles from this grid.
tri1 = gi_corners[:,[0,1,3]]
tri2 = gi_corners[:,[1,2,3]]
triangles = np.vstack([tri1,tri2])Using matplotlib we can visualise the triangular mesh.
import matplotlib.pyplot as plt
fig,ax = plt.subplots()
ax.triplot(vertices[:,0],vertices[:,1],triangles)LoopStructural is the open source 3D geological modelling library that is the 3D modelling module of the Loop project. The code has been written in an object oriented modular format to make it easy to add functionalities and to extend the codebase. In this blog post I will demonstrate the steps that were required to implement an iterative gradient norm constraint that was suggested by Gautier Laurent.
The problem that we are trying to solve is the change in the magnitude of the gradient norm of the implicit function, as a result of overconstrained gradients. This was identified in Gautier Laurents 2016 paper “Iterative Thickness Regularization of Stratigraphic Layers in Discrete Implicit Modeling” published in Mathematical Geosciences.
Within discrete implicit modelling the gradient of the implicit function $ \nabla \phi(x,y,z) $ can be expressed as:
\[\nabla \phi(x,y,z) = \textbf{T} \cdot \phi_c\]where $\textbf{T}$ is a matrix representing the derivative of the shapefunction (e.g. linear tetrahedron) and the Jacobian of the coordinate transformation and $\phi_c$ are the values of the vertices of the discrete mesh.
The norm of the implicit function is: \(|\nabla \phi|^2 = \nabla \phi ^T \cdot \nabla \phi = \phi_c^T \cdot \textbf{T}^T \cdot \textbf{T} \cdot \phi_c\)
This equation is quadratic and cannot easily be incorporated into the linear approach for solving the implicit models.
Gautier’s solution was approximate the gradient norm by using an estimation of the direction of the gradient ($u$) to constrain the norm of the implicit function.
\[|| \nabla \phi || \approx \textit{u}^T \cdot \textbf{T} \cdot \phi_c = \frac{1}{L}\]This constraint can be applied iteratively where the implicit function is evaluated without the gradient norm constraint and this is applied iteratively, either increasing the weight or increasing the number of constraints. In this post I will demonstrate how this was added into LoopStructural.
LoopStructural implements two discrete implicit modelling approaches: 1) using a tetrahedron support where the regularisation minimises the variation in the implicit function gradient between neighbouring elements. 2) using a Cartesian grid where the regularisation is a minimisation of the second derivative
Both of these discrete interpolators share the same base class, DiscreteInterpolator, which manages the assembly of the least squares system and solving of the least squares problem. When a constraint is added to the implicit function the method add_constraint_to_least_squares is called taking the value of the constraint, the node index of the constraint and the right hand side of the equation. The implicit function is solved by assembling a sparse (MxN) matrix where M is the number of constraints and N is the number of degrees of freedom.
The implicit function is: \(A \cdot \phi_c = B\)
and can be solved in a least squares sense
\[A^T \cdot A \cdot A^T \cdot B = \phi_c\]In LoopStructural v1.3.7 the linear equations were solved when ._solve(solver=’cg’,**kwargs) was called.
logger.info("Solving interpolation for {}".format(self.propertyname))
self.c = np.zeros(self.support.n_nodes)
self.c[:] = np.nan
damp = True
if 'damp' in kwargs:
damp = kwargs['damp']
if solver == 'lu':
logger.info("Forcing matrix damping for LU")
damp = True
if solver == 'lsqr':
A, B = self.build_matrix(False)
else:
A, B = self.build_matrix(damp=damp)
## runs appropriate solver given solver argumentTo implement the constraints that Gautier suggests we need to apply the following algorithm
We can do this by defining a function
def constant_norm(feature):
# find centre of element and calculate gradient
bc = feature.interpolator.support.barycentre()
element_gradients = feature.interpolator.support.get_element_gradients()
v = feature.evaluate_gradient(bc)
v/=np.linalg.norm(v,axis=1)[:,None]
T = feature.interpolator.support.calc_T(bc)
bc = feature1.interpolator.support.barycentre()
# calculate gradient for every element for previous iteration
# get vert indexes for all elements
elements = feature.interpolator.support.get_elements()
vertices = feature.interpolator.support.nodes[feature.interpolator.support.get_elements()]
vecs = vertices[:, 1:, :] - vertices[:, 0, None, :]
vol = np.abs(np.linalg.det(vecs)) # / 6
# previous iteration gradient \cdot current iteration T1
a = np.einsum('ij,ijk->ik', v, element_gradients[:,:,:])
# weighting by volume was causing odd results
a *= vol[pairs[:,0], None]
idc = elements
B = np.zeros(a.shape[0])
rows = np.tile(np.arange(a.shape[0]),(a.shape[1],1)).T
A = coo_matrix((a.flatten(), (rows.flatten(), idc.flatten())),
shape=(a.shape[0], feature.interpolator.nx),
dtype=float)
ATA = A.T.dot(A)
ATB = A.T.dot(B)
return ATA,ATBThis can then be applied iteratively to the model:
def iterative_constant_norm(feature,ninter):
from scipy.sparse.linalg import cg, splu
# solve without constant norm
feature.interpolator.solve_system(solver='cg',tol=feature1.builder.build_arguments['tol'])
for i in range(1,niter):
print('iteration: {}'.format(i))
A, B = feature.interpolator.build_matrix()
# calculate constant norm
ATA, ATB = constant_norm(feature)
# increase weight for each iteration
ATA*=w*((i**2+1)/(niter**2))
# combine base matrix and constant norm matrix
A+= ATA
B+= ATB
# solve using conjugate gradient
soln = cg(A,B,tol=f.builder.build_arguments['tol'])
# update feature node values
f.interpolator.c = soln[0]
To add the gradient norm constraints we need to be able to modify the A matrix and B matrix between iterations to update
To add the constraints for the gradient magnitude norm the re solved using the _solve(A,B,solver=’cg’) method which is called from solve. To add the gradient norm constraints we need to modify A and B to incorporate the new In order to add the gradient norm constraints this The dFor both approaches the implicit function is was assembled by
We recently submitted another paper to the Loop3D special issue in Geoscientific Model Development. The paper is currently in discussion phase of the peer review but you can download it here.
The paper provides a conceptual and technical overview of how faults are incorporated into 3D models inside LoopStructural. This involves building a curvilinear coodinate system (fault frame) for the fault using the fault surface, fault slip direction and the fault extent. Within the fault frame the geometry displacement is defined by combining three functions describing the displacement within the fault ellispoid. The kinematics of the fault are characterised by gradient of the fault slip direction coordinate multiplied by the fault displacement. Faults are incorporated into the model by modelling the most recent fault first and using the kinematics of this fault to restore any feature overprinted by this fault. This is done before interpolating the older feature and the same function is used to incorporate the fault into the faulted surface.
The most recent version of LoopStructural addresses some minor bugs and adds a few small improvements for visualisation. The major changes are:
Other minor changes are outlined on the documentation changelog here.
To install LoopStructural pip install LoopStructural or conda install -c loop3d -c conda-forge LoopStructural
Uncertainty in 3D geological models is challenging to simulate because the models used to represent geology are generally parameterised by the observations that are used to assess the quality of the mdoel. Geological uncertainty can be split into three components:
The Mountain bike park planned for Warburton has been extremely controversial with social and environmental concerns regularly voiced by critics. An Environm...
Triangular meshes can be used for representing surfaces in 3D, can be used for interpolation and other modelling. You can extract a triangular mesh using mar...
LoopStructural is the open source 3D geological modelling library that is the 3D modelling module of the Loop project. The code has been written in an objec...
We recently submitted another paper to the Loop3D special issue in Geoscientific Model Development. The paper is currently in discussion phase of the peer re...
The most recent version of LoopStructural addresses some minor bugs and adds a few small improvements for visualisation. The major changes are: Faults add...
Uncertainty in 3D geological models is challenging to simulate because the models used to represent geology are generally parameterised by the observations t...